
おはようございます。草井真良です。
前回と前々回の記事で取り上げた「Stable Diffusion」と「Waifu Diffusion」ですが、先日ローカル環境でやっと動かせたので備忘録を兼ねてここにメモします。上の画像もそれらで描きました。
上のリンクに詳しい使い方が載っています。
私はAnacondaを使って動作させましたが、リンク先のようにAnacondaを使わないやり方の方がシンプルでやりやすいと思います。
http://127.0.0.1:7860/ に繋がるようになったら完了です。
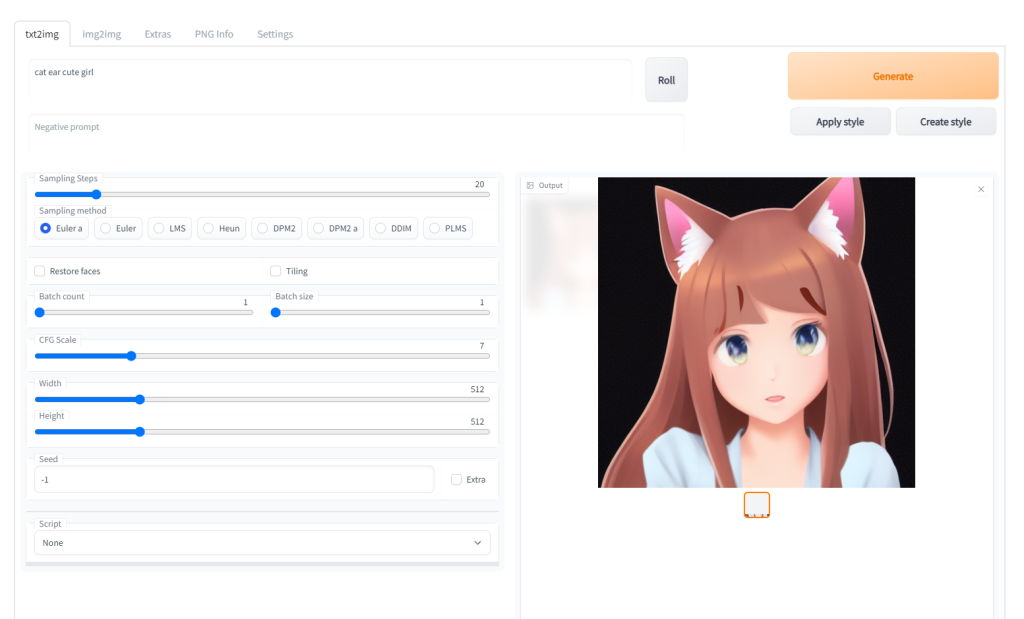
こんな感じです。
「txt2img」はテキストから画像生成、
「img2img」は上記に加えて画像(とテキスト)から画像を生成もしくは編集できるモードです。
「extras」は画像を拡大補正できる機能です。
それで使ってみた感じとしては、成人向けの画像生成は予想以上に弱いなと思いました。
わいせつ画をimg2imgにかけてRedrawしてみた所、何故か芸術作品に出てくる前衛的なオブジェの絵が出てきたので掲載します。


こんな感じです。
元の絵は見せられないのですが、AIはわいせつな分野には弱い分野だとは思いました。
反面、一般向けの、特に写実的な分野では数年で追いつかれるかもしれないと思いました。
とりあえず今即座に使えるのはExtraの画像拡大補正機能です。
これが結構綺麗に拡大できて、Twitter等で保存した画像を大きくきれいな画像で保管したい用途には役立ちます。
今回はそんな所でしょうか。
この記事が面白かったと感じた方は他の記事も見る、もしくはここにコメントをください。
他にもアマゾンや楽天の広告から商品を買ったりしてくださると収益が入るので励みになります。
欲しいものリストや仮想通貨での投げ銭も嬉しいです。
お読みいただきありがとうございました!


コメント